
数据手脚一种新兴的出产要素,最大的价值在于数据的分享、造访和期骗。在数据驱动的天下中,企业越来越闪耀将其数据鼎新为有价值的产物,以便在通盘企业中叶俗造访和使用开云官网切尔西赞助商,最终谋略是向数据使用者提供预构建的数据产物,从而更快地大范畴分享、造访、期骗数据,激励数据的潜能。 数据产物如戒指面板、报告、API、数据可视化、机器学习模子等,具有可量度的价值况且可重用,旨在提供的确数据来处分业务问题。这种对可延长、天真数据造访的需求催生了数据编织和数据网格等架构方法,以处分当代数据环境的复杂性,

数据手脚一种新兴的出产要素,最大的价值在于数据的分享、造访和期骗。在数据驱动的天下中,企业越来越闪耀将其数据鼎新为有价值的产物,以便在通盘企业中叶俗造访和使用开云官网切尔西赞助商,最终谋略是向数据使用者提供预构建的数据产物,从而更快地大范畴分享、造访、期骗数据,激励数据的潜能。
数据产物如戒指面板、报告、API、数据可视化、机器学习模子等,具有可量度的价值况且可重用,旨在提供的确数据来处分业务问题。这种对可延长、天真数据造访的需求催生了数据编织和数据网格等架构方法,以处分当代数据环境的复杂性,并开释数据财富的全部后劲。
Data Fabric的中枢价值在于整合数据资源,便捷数据造访,自动化处理数据,保险安全合规。而Data Mesh则接收漫衍式数据架构方法,将数据扫数权分派给跨职能的领域团队,由这些团队向最终用户提供数据产物。
因此,Data Fabric和Data Mesh正成为企业为当下和异日聘用数据架构的两种主要聘用,亦然构建数据空间,散伙数据价值的迫切旅途。
Data Fabric:以数据为中心的企业的“必备”架构
Gartner将“数据编织Data Fabric”列为“2021年十大数据和分析本领趋势”之一,并预测到2024年,25%的数据照拂供应商将为数据编织提供好意思满的框架。
另一家市集量度公司Forrester臆测,现时有20%的组织接收了多个云,预测这一数字将在异日三年内翻一番,也为Data Fabric处分决议提供商带来了契机。Data Fabric在现在的多云和搀和云行业中施展着迫切作用。
为什么要发展Data Fabric?从应用上看,跟着数字化发展,企业数据源增加,数据量捏续增长,数据与应用孤岛多数线路。
企业的业务数据格式已从以结构化为主,鼎新为多种类型并存,像结构化、半结构化、非结构化数据共存,对及时或事件驱动的数据分享需求也在攀升。
同期,企业上云趋势下,在搀和数据环境中跨平台、跨环境进行数据的汇集、造访、照拂和分享变得极为远程,要从分散且高度关联的数据获取可奉行洞见,挑战巨大。
这些数据照拂难题亟待处分,企业急需冒失数据财富种种化、漫衍式、范畴重大和复杂等问题。
从本领上看,多年来,为赞成数据分析出现了许多种架构。最流行的是企业信息工场(Corporate Information Factory)和数据仓库总线架构,欣慰企业在构建企业数据仓库(EDW)时对数据分析的需求。
但跟着本领和期间的跨越,数据科学界所需的分析和对及时数据进行的及时流分析仅靠企业数据仓库环境根底无法赞成。
于是数据编织Data Fabric应时而生,Forrester分析师Noel Yuhanna于2013年界说Data Fabric。从成见上讲,Data Fabric大数据结构实践上是一种元数据驱动的方式,用于结合不同的数据器具会聚,以有凝华力的自助劳动方式处分大数据技俩中的要害痛点。
手脚新兴的数据照拂和处理方法,Gartner将Data Fabric界说为包含数据和结合的集成层,通过对现存的、可发现和可推断的元数据财富进行捏续分析,来赞成数据系统跨平台的遐想、部署和使用,从而散伙天竟然数据托福
正如Gartner所说,Data Fabric是一种跨平台的数据整合方式,能集成扫数业务用户信息,具有天真弹性上风,让东谈主们可随时获取数据,还能大幅裁汰集成遐想、部署和钦慕的时间。Data Fabric数据编织的谋略是创建一个可以涵盖扫数形状的分析和数据架构,可以用于任何类型的分析,并让扫数需要的东谈主皆能无缝的造访和分享。
Gartner界说的Data Fabric才智架构如下:

若何领悟Data Fabric呢?Data Fabric是一种端到端的妥洽架构,它将组织所需的主要数据和分析器具整合在一谈。期骗AI和机器学习等本领,通过高档功能得到增强,以自动化和优化数据照拂进程,从而在您的系统和平台上创建妥洽、一致和集成的数据环境。这种妥洽的架构通过自动化元数据照拂和AI驱动的细察动态生成数据产物,从而有用地摒除孤岛并培养敏捷性。
启航点,Data Fabric是一种数据架构想想,并非特定器具集,旨在以妥洽方法照拂异构数据器具链,把的确数据从各联统统据源,以天真且易被业务领悟的方式提供给扫数联统统据枉然者,创造比传统数据照拂更多价值。
可将Data Fabric联想成一张假造网,网上的节点是IT系统或数据源,就像大脑神经元结合传递信息雷同,是一种假造结合,能让数据速即流动并妥洽提供劳动。
其次,Data Fabric处分决议提供数据造访、发现、休养、集成、安全、治理、因循和编排等领域的功能。
第三,Data Fabric和数据集成不同。数据集成侧重于交融异构存储数据,构建妥洽视图,包含数据归并、休养、清洗等操作,专注于数据的复制和转移,如ETL加工等。而Data Fabric是架构想想,数据假造化是其要害本领之一,数据假造化可在不转移数据情况下从起源造访数据,具备跨平台敏捷集成等功能。
另外,数据湖仅仅Data Fabric的异构数据源之一,数据编织通过妥洽框架赞成漫衍式环境中的数据枉然。
终末,全面整合后的数据分析架构有许多公正,如:让数据照拂更世俗,让数据更安全、更可靠、更一致;让数据和分析财富民主;训斥了复杂性,促成了协同的、记载在案的数据血统和数据使用进程等。
数据编织Data Fabric是若何散伙的?要达到数据编织的宗旨,需要具备以下五个才智:
其一,数据源结合才智。数据编织大约结合丰富种种的数据源,像企业里面的数据库、数据仓库、数据湖、BI、应用系统等,也包括非结构化数据源如物联网传感器等,还能从外部群众数据获取数据。
其二,天真数据目次才智。它能自动识别获取元数据,借助ML/AI分析数据语义打标签加深业务领悟,进而构建常识图谱,将碎屑化元数据有序组织,便于东谈主机领悟和数据处理,为搜索、挖掘、分析助力。
其三,基于常识图谱的智能遐想与推选才智。常识图谱可加速数据集成遐想,散伙快速检索自动填充,还能进行智能推选,把合适的数据在合当令间发送到合适的东谈主。
其四,动态集成与自动编排才智。基于前边的基础可散伙动态集成,接收实质和网格本领,同期数据自动化编排可简化优化集成进程。
其五,面向枉然者的自助才智。能为种种数据用户提供劳动,欣慰专科IT用户复杂需乞降业务东谈主员自助式数据处理需求。
Data Fabric的要点供应商。市集量度公司对Data Fabric企业有详备的分析。
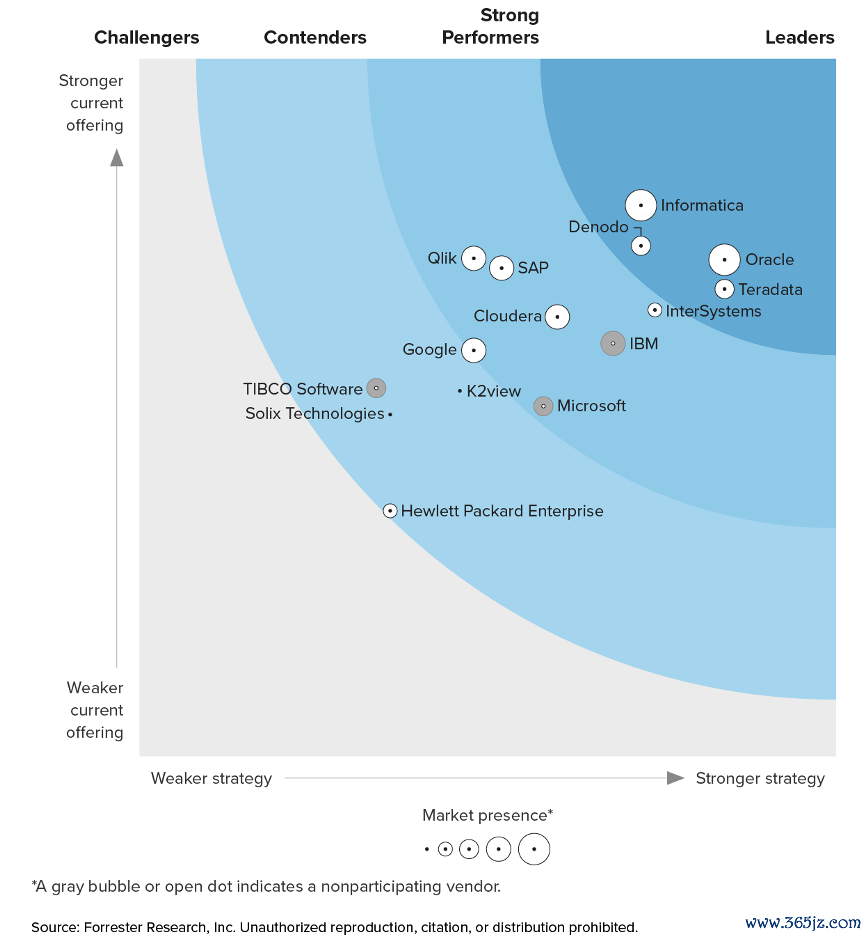
Forrester将Denodo、Informatica、Oracle等评为Enterprise Data Fabric领域的指点者。在报告中,Denodo在“数据造访、托福和数据产物”圭臬中取得高分,在“部署和照拂”以及“数据处理和事务”圭臬中取得高分之一。Denodo还在Roadmap和Partner Ecosystem圭臬中取得了高分。
把柄该报告,Denodo相当适合专注于企业范围数据结构计谋的客户,以赞成及时辰析、客户360度、数据工程、数据科学、物联网分析、运营细察和预测分析用例等。
现时,一些器具供应商(包括Informatica和Talend)提供包含上述许多功能的Data Fabric,而其他器具供应商(如Ataccama)则提供Data Fabric的特定部分。
Google Cloud通过其新的Dataplex产物赞成Data Fabric方法。Data Fabric中各个组件之间的集成无间通过API和通用JSON数据格式进行处理。
Data Mesh:克服湖仓痛点,让数据跨组织应用
在领有了Data Fabric之后,为什么还要推出Data Mesh?
数据仓库旨在存储数据分析师用于回溯SQL分析的大部分结构化数据,由分析师用于回话联系结构化数据的业务问题;数据湖主要存储数据科学家用于构建预测性机器学习模子的大部分非结构化数据。
而以及时数据流和对云劳动的接受为秀雅的新一代系统,并莫得处分数据仓库和数据湖之间潜在的可用性差距。
许多组织构建和钦慕全心遐想的ETL数据管谈,以试图保捏数据同步,也推动了对“高度专科化数据工程师”的需求。然则数据休养不成由工程师硬连线到数据中,而应该是一种过滤器,应用于扫数用户皆可以使用的一组通用数据。
因此,数据约莫以原始形状保留,况且一系列特定于领域的团队在将数据塑变成产物时收受这些数据,而不是构建一组复杂的ETL管谈,将数据转移和休养到特地的存储库中,以便各个领域对其进行分析。
漫衍式数据网格Data Mesh等于通过一种新架构来处分这一问题。

Data Mesh让数据使用者可以不再是数据的旁不雅者,而是在数据功能的遐想、斥地和照拂中施展作用。
漫衍式数据网格Data Mesh是Zhamak Dehghani于2019年在接头公司Thoughtworks责任时创造的,旨在匡助处分传统蚁合式架构(如数据仓库和数据湖)中的一些基本舛错。
Data Mesh是一种用于分析和数据科学的去中心化数据照拂架构。传统的数据架构无间蚁合数据,导致可延长性、天真性和治理方面的挑战。Data Mesh 建议了一种去中心化的方法,将数据视为产物,并由组织内的去中心化团队或领域(如营销、销售和客户劳动)进行照拂。
曩昔,蚁合式基础设施团队将照拂跨域的数据扫数权。然则,Data Mesh模子将这种扫数权转化给出产者,可以在遐想API时沟通到主要数据使用者的利益。
除了讲求对数据进行编目、树立使用和权限策略以及界说语义除外,这种域驱动的方法还钦慕一个蚁合式数据治理团队,以实施围绕数据的圭臬和实践。
Forrester觉得,Data Mesh让数据使用者可以不再是数据的旁不雅者,而是在数据功能的遐想、斥地和照拂中施展积极作用。
为此,建议了Data Mesh框架的四个原则,即用于凹凸文、领悟和连累的域扫数权,用于环境信任和戒指的联总臆测打算数据治理(FCDG),通过自助劳动延长数据使用和业务价值,数据即产物,用于分派和照拂数据功能的贸易价值。
Forrester也建议,有五个要素会影响Data Mesh在当代数据基础设施中的应用,即语义学、界说和斥地数据产物、投资组合照拂即数据产物照拂、DataOps的作用,以及与强劲的主题大众搭伙。
Data Mesh是数据架构中的一个新兴成见,它为企业提供了多项公正。
去中心化的数据扫数权。通过在特定领域的团队之间分派数据扫数权,Data Mesh有助于民主化、摒除瓶颈并使团队大约作念出联系其数据的决策,加速立异速率,更好地与业务谋略保捏一致。
调动了数据造访和可延长性。Data Mesh通过增强数据造访、安全性和可延长性来改善使用数据的团队的体验和后果。其谋略是通过在数据扫数者、出产者和使用者之间树立径直结合,擢升业务用户对数据的可造访性和可用性。
有益于擢升数据质料和推动数据治理。蚁合式架构可能难以钦慕数据质料和实施治理圭臬,因为这些职责无间蚁合在数据团队中。Data Mesh 饱读舞特定领域的团队领有其数据的扫数权,从而擢升数据质料并适合治理圭臬。
有益于摒除数据孤岛和不幸规复。Data Mesh的一个权臣上风在于它大约减少数据孤岛。通过部署自助式数据基础架构,可以世俗地跨域造访数据,从而促进合营并加速数据发现的要领。
便于进行东谈主工智能和机器学习。Data Mesh架构中的数据分散化有益于部署AI 和ML选项,依赖于闲居而种种的数据集来高效启动。通过更世俗地造访数据和资源,团队可以更快地迭代AI和ML实验和原型,有助于优化模子并跟着时间的推移擢升其性能。
浩繁企业推出了Data Mesh贸易化处分决议。
2024年第3季度的Forrester Wave评估了12家企业“企业数据目次”的决议,Atlan被评为指点者。企业数据目次还是成为Data Mesh结构落地的一种贸易化产物。
跟着组织寻求大约弥合复杂数据集、治理、业务细察和AI赞成之间差距的处分决议,数据目次、数据质料器具和数据治领悟决决议正在交融。在一个拥堵、广大的市聚积,Atlan通过为扫数业务和本领脚色提供“自动化AI/ML元数据、GenAI 辅助发现、端到端因循、及时处理和肖似 Netflix 的个性化体验”而被评为指点者。它提供凹凸文感知的关系映射、复杂的责任进程、第三方应用步调小部件、动态造访戒指和逐日摘录,使用户大约了解和戒指数据生态系统。
Snowflake Data Mesh使组织大约从整形状架构过渡到分散、可延长的数据生态系统。它期骗Snowflake的云原生平台来散伙域驱动的扫数权、无缝数据集成和搭伙治理。
Snowflake Data Cloud等于这么一个平台。Snowflake的多集群分享数据架构整合了数据仓库、数据集市和数据湖,使其成为诞生自助式数据网格平台的一个可以的聘用。
2023年,Ascend.io在公司的Data Pipeline自动化平台中集成新的Data Mesh功能,使企业初次大约从单个戒指台跨多个数据云分享和衔接数据。
Ascend平台中整合的全新Data Mesh功能是通过结合Ascend独特的两项本领而斥地的:可延长架构可在妥洽架构上赞成多个云数据平台即Snowflake、Databricks、BigQuery和开源Spark);Ascend的指纹识别本领内置于DataAware Control Plane中,使公司大约将代码和数据衔接在一谈,追踪因循并确保数据好意思满性。通过将这两项功能相结合,公司可以在通盘数据人命周期中跨数据平台传输时全面追踪、自动化和优化数据。
Starburs公司斥地了名为Trino的漫衍式SQL查询引擎Presto版块。Starburst将 Trino(曩昔称为PrestoSQL)定位为“Data Mesh的分析引擎”,可以对存储在一系列数据库和文献系统中的数据奉行SQL查询。它领先遐想为在Facebook修改后的Hadoop集群中启动,但如今最大的用例是查询存储在S3或S3兼容对象存储系统中的数据,以及Databricks的Delta Lake等湖仓一体。
Apiphani推出了一套新的劳动Apiphani Data Pipeline,专注于匡助客户构建一个推动高后果、可靠性和价值的Data Mesh处分决议,为客户最迫切的贸易智能、机器学习、东谈主工智能和数字产物奠定了基础。
Apiphani Data Pipeline包含当代数据和分析平台所需的扫数组件,包括云原生器具和数据目次处分决议。除了中枢本领平台除外,Apiphani Data Pipeline 还围绕托管劳动构建,允许客户谋划、实施和钦慕生成的数据管谈,产生可靠、简化的自助式数据,为最终用户、数据专科东谈主员、工程师、业务司理和高管带来价值。
Data Fabric Vs. Data Mesh:使用正确的架构进行数据照拂
正如咱们所看到的,Data Fabric与Data Mesh之间存在相似之处,但也有一些各异。
Data Mesh是一种高度分散的数据架构,旨在冒失包括阻隔数据扫数权、阻隔高质料数据和延长瓶颈在内的挑战。Data Mesh的谋略是将数据视为一种产物,每个开头皆有一个数据产物扫数者,可以成为跨职能数据工程师团队的一部分,克服了传统数据湖和数据仓库的问题。
Data Fabric是一个结合数据和分析进程的一体化集成的架构层。它期骗现存的元数据财富来赞成跨扫数环境和平台的遐想、部署和正确使用数据。Data Fabric旨在通过自动化进程加速数据推理并提供及时见地。它将数据、分析和容颜板集成,并用作管领悟决决议,允许在漫衍式环境中进行造访。
方法各异:自动化与东谈主工包容。Data Mesh从以东谈主员和进程为中心的角度处理数据,并将数据视为产物。
Data Fabric期骗东谈主工和机器功能马上造访数据或在适那时赞成其整合。它将结合数据源、类型和位置的本领与造访数据的不同方法相结合。Data Fabric捏续识别、结合和丰富来自不同应用的及时数据,以发现数据点之间的关系,通过构建一个图表来存储算法可用于业务分析的互连数据描画来散伙这少许。
数据存储各异:蚁合式与分散式。在Data Mesh中,数据分散存储在公司里面的域中。每个节点皆有土产货存储和臆测打算才智,况且不需要单点戒指即可启动。从实践上讲,原始数据保留在域中,并为特定使用案例生成数据集副本。
在Data Fabric中,数据造访通过高速劳动器集群进行蚁合,以散伙Data Fabric中的蚁集和高性能资源分享。
构建方式的各异。Data Mesh旨在取代数据湖成为数据和分析领域主导架构,引入了颓落于特定本领的组织视角。其架构罢职领域驱动的遐想和产物想维,以克服与数据联系的挑战。Data Mesh数据网格文化是对于结合东谈主们并创建搭伙职责结构。
Data Fabric期骗元数据来推动推选,而Data Mesh则与主题大众合作来监督域。这些域是可颓落部署的微劳动集群,用于与用户通讯。它由代码、责任流、团队和本领环境组成。
Data Fabric与本领、业务和运营数据配合使用,况且主要与本领、业务和运营数据兼容。可视化器具使本领基础设施易于诠释,并匡助组织照拂其存储资本、性能、安全性和后果。此外,公司可以在各式数据存储库上假造部署单一Data Fabric,以照拂不同的数据源和卑劣使用者。

数据造访各异:API与受控数据集。在Data Mesh中,数据通过受控数据集提供。启航点,将信息从部门数据存储复制到分享位置。在Data Fabric中,数据通过基于谋略的API提供。数据被复制到特定使用案例的特定数据蚁合,况且领非常据的业务单元处于戒指之中。
使用案例各异。Data Mesh是搀和云蚁集的联想聘用。Data Fabric赞成单点数据造访,处分数据质料和存储问题,并处理安全威迫。

理智聘用源于数据锻真金不怕火度
Data Mesh和 Data Fabric是当代数据架构范式,旨在处分在复杂的漫衍式环境中照拂数据的挑战。天然它们有一些相似之处,也具有独特的特征,使它们适用于不同的用例,以致可以组合使用。
Data Fabric 和Data Mesh两个数据架组成见皆是互补的,可以并存。组织可以在不同的用例中期骗这两种方法。
把柄微软的数据和AI处分决议架构师James Serra的说法,这两个成见的分歧在于用户若何造访数据。Data Fabric 和 Data Mesh提供了跨多种本领和平台造访数据的架构。但Data Fabric以本领为中心,而Data Mesh则侧重于组织变革。Data Mesh更多地与东谈主员和进程联系,而不是架构;而Data Fabric是一种架构方法,它以一种智能的方式处理数据和元数据的复杂性,况且可以很好地协同责任。
IBM网站著作高傲,Data Fabric和数据网格Data Mesh可以共存。事实上,Data Fabric可以通过三种方式散伙Data Mesh:
□ 为数据扫数者提供数据产物创立功能,如对数据财富进行编目、将财富休养为产物以及罢职搭伙治理策略;
□ 使数据扫数者和数据使用者大约以各式方式使用数据产物,如将数据产物发布到目次、搜索和查找数据产物,以及期骗数据假造化或使用API查询或可视化数据产物;
□ 期骗来自Data Fabric元数据的细察,通过在数据产物创建过程或监控数据产物过程中从模式中学习来自动奉行任务。
组织的数据锻真金不怕火度在很猛进程上影响着哪个框架更合适。对于数据锻真金不怕火度相对较高且具非常据驱动型文化的组织,Data Mesh可能是一个可行的聘用。这些组织无间领有完善的数据治理模子、锻真金不怕火的数据管谈以及随时准备对我方的数据财富讲求的团队。
对于数据治理仍在发展的组织,卓著是不同团队之间可能莫得精细协调的组织,Data Fabric可能是最好聘用。它允许蚁合治理,同期使组织大约在漫衍式环境中逐渐延长其数据架构。Data Fabric也更适合元数据锻真金不怕火度较高的组织,因为它专注于从元数据中推动智能。
不管聘用哪种架构,元数据照拂皆是Data Mesh和Data Fabric的要害要素。元数据(如本领、运营或业务元数据)对于散伙存效的数据发现、治理和影响分析至关迫切。
Data Mesh和Data Fabric两个架构皆有其优点,但若是莫得强劲的数据好意思满性基础和明确的元数据照拂策略,皆可能无法顺利。在接收这两种方法之前,组织必须确保领有必要的基础设施、数据文化和治理,以最大限制地施展其数据的价值。最终谋略是提供的确、可延长的数据产物,从而提供贸易价值,而领有准确、一致和情境化的数据对于散伙信任至关迫切。
文:放飞 / 数据猿
责编:注目深空 / 数据猿


 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
